Am I Misusing the AWS Cloud Development Kit (CDK)?
It recently became necessary for me to maintain a few databases in a system. Those databases had a specific (read-only) role in the system. Standard RDS instances restored from a snapshots was all we needed.
Those initial few was going to grow to dozens. There were other solutions, but in the end the one that made the most sense was a CloudFormation template that would manage these databases. If new data was needed, snapshot ID's were updated in the .yaml and a changeset was executed. The existing databases were torn down and new databases created. Everybody was happy.
Ugh, large CloudFormation templates.
This was quickly going to grow to managing more than just a few databases and the chance for user error was too high. Automation was required so that it was reliable and timely. So, I set out to create a CDK module that managed updating and executing this CFN template. Because, of course.
All the data driving this process could easily be represented in a JSON file which made maintenance and re-synthing very easy. Except the snapshots. Those I would update manually. While it wasn't ideal it worked and any request to update databases usually took me less than a few minutes to execute.
Here's a diagram:
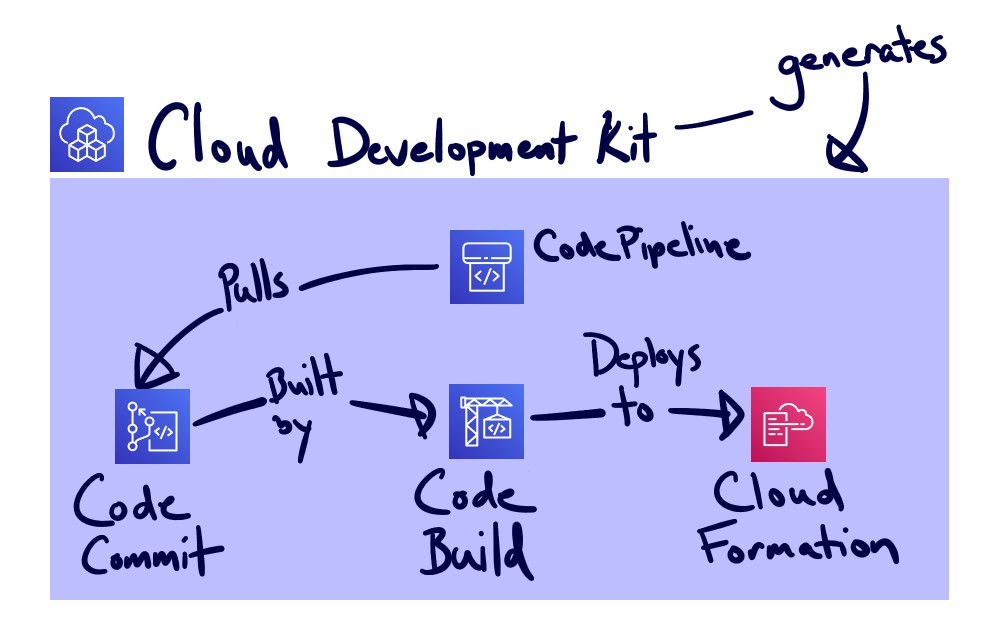 What the automation basically looks like.
What the automation basically looks like.
But what Snapshot ID to use? When I did this process manually it was at request from the devs and always followed the dev teams loading some data into the source systems. I would run a script that would create manual snapshots with a well-defined ID. Updating the CloudFormation template was a simple `sed` or find/replace to the new ID. Could I do this process in the automation as well?
Perhaps I could, but doing so felt complex and unnecessary, since we already had snapshots of the databases being taken automatically. My existing CDK module then would need to actively read the source DB instances through AWS API calls and update the CDK Construct accordingly.
It was pretty painless to work into the existing code I had and it was immediately obvious how making arbitrary API calls to drive the logic of how to build those Constructs was very powerful.
I'm going to be doing a lot of that in the future.
However, I don't actually understand why it works.
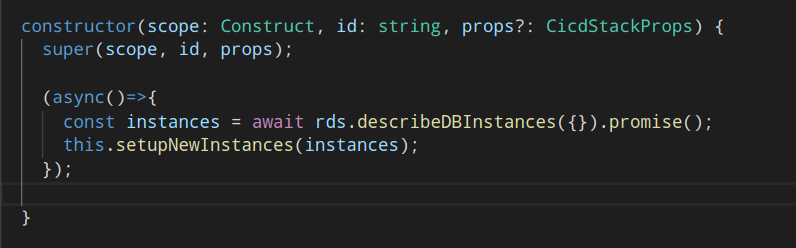
In my Typescript code I am using async/awaits to read data from the AWS API. That data then drives the creation of the CDK Constructs and therefore the CFN templates. But my code to create those Constructs comes after the `await` and the constructor for my Stack is finished before all the work is done. How does the CDK know that all my async calls are done, and it can turn those objects into YAML? Does it just let the Constructs settle for a moment before reading them?
Using async/await in CDK Constructs
I'll have to dig into the code more later to understand it. But, I don't trust that it will always work.
But should I be able to?
I had a very informative discussion with Ben Kehoe recently about the CDK. He's got excellent points about the CDK and what it means to CloudFormation and the surrounding ecosystem.
It did make me look at the CDK in a new light. I've been thinking "is this proper?" more often about how I use it. In this case, I don't know whether it is within the spirit and intent of the CDK Team to make this type of functionality possible. Can I continue doing this type of async/await calls in my CDK modules (because it's super useful!) and know it will work and is likely to be properly supported?
Or did I get lucky?