AWS's new NoSQL Workbench for DynamoDB is out! Is it for you?

The AWS Consoles DynamoDB client has been my goto client for editing data in DynamoDB. If I've got tables to create or manage, I'm doing that with CloudFormation ( or the CDK).
Now AWS has released a desktop UI client for DynamoDB, the NoSQL Workbench , that has features of both. I'm going to cover some of my initial thoughts of the product; I'll cover where it's strong, and where it's weak.
What, no Linux?
Windows and Mac are first up on the supported OSes. I'm hoping Linux is just around the corner. Out the gate the app looks quite nice. Just taking a guess but I'm assuming it's not another Electron app. Only a few minor visual ticks were spotted and they were mostly cases of mid-word wrapping of text. The splash screen clearly lays out what you should be expecting from this tool.
 Pretty!
Pretty!
Immediately I was dropped into the Data Modeler. I could have choosen to create a new model, but I started with importing a sample model. I wanted to see what they consider a good example of a model and how it's setup in this tool. I picked the AWS Discussion Form option. I got three tables, Forum, Thread, and Reply. Nice and easy to understand model. So far, so good...
This type of feature - supplying sample data - is a great way to get new users to quickly understand how the tool works and how it will represent models people are already pretty familiar with or can grok easily. This is something I was familiar with using Dyanamics GP and Microsoft's Fabrikam company. I always found it comforting to have a reference design I could go back to.
At this point I just stepped through the models and reviewed the setup and options I had in front of me. Since I already understood a lot of DynamoDB concepts none of this seemed odd or out of place. It felt like a nice tool for doing some hands-on data modeling. However, if this was my first venture into NoSQL - as I suspect DynamoDB is for a lot of people - I would probably feel a little confused on what various options meant. The sample data helps mitigate some of this, as that becomes documentation in its own right. But, if this tool is going to be an entry point into DyanmoDB some additional guidance for the user will be needed.
Once I was happy with the model, I looked for options to use it. This is where I was disappointed. I could push these table defintions straight to AWS, assuming I gave it access keys. But, I'm never going to use that option. I manage everything by CloudFormation and like it ... [ducks]...
However, it can export out a JSON representation of the data model. This is good, because I can now plug that into a little CDK code and I can generate the CloudFormation templates I need.
Here's to hoping that this tool will just incorporate some sort of translation to CloudFormation in the future.
But wait, there's more!
But of course, modeling isn't all this tool does, so let's keep going. Next option down the left-hand side navigation is the Visualizer. This was the part I was most excited about! The web-based Console UI is... well.. I use it, but I don't like it. There are too many occassions during development where editing data inline is powerful and the Console makes that barely usable. But CLI and Node clients aren't going to be faster options.
Clicking around and I get to see all the sample data I had loaded with the data model. The table displays the varying document bodies intelligently in a table. This is great for both development and, my new passion, speaking/teaching engagements. This is already much better than the web-based Console. The UI is generally responsive and works as expected. Going to be taking lots of screenshots of this in future talks/blogs/documentation.
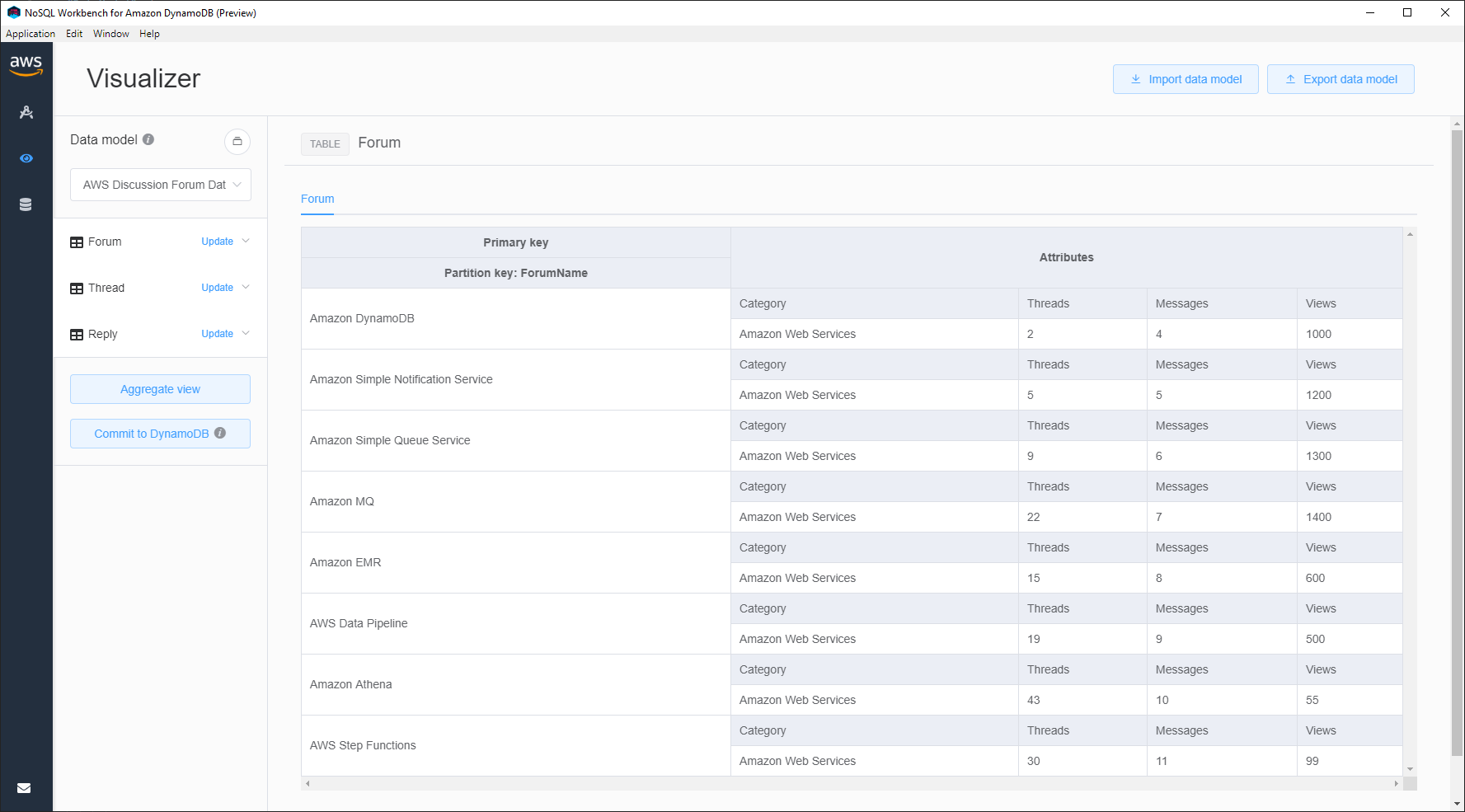 That's a nice table
That's a nice table
The only real hitch came up when I loaded a table from one of my test systems. The table had approx 12000 records in it. Overall pretty small. However, the UI did choke a bit on processing that data.
That execute button stayed disabled for quite some time
And before you say "well yeah, that's a scan for you" understand I also tried with a 'query' operation with the same results. Actually, after the 12000 records were loaded the UI became quite laggy. These kind of performance fixes are likely already coming. This is still an early release.
Can it go 3/3?
The Operation Builder is the third and final option in the left-hand menu. I was expecting this to give me the ability to edit data in the tables. Mostly because it was the third and final option, and I hadn't see it in the other two sections of the app. Editing data quickly and in a nice UI is pretty much the only reason I go to the AWS Console. While it's not great, it gets the job done. I'm eager for something that can replace it.
Unfortunately, the Operation Builder won't be it. But, that's ok, because what you get here is a clear and well enforced method to editing data in an environment. Properly operating on a DynamoDB in your application code is a skill that takes effort to hone. It is fundamentally different with how you typically operate against a table in a traditional RDBMS system. They're teaching right methods from the start and that is good.
This tool will help train and explain how operations against a DynamoDB table needs to occur. At the end, you get to generate code for your favorite language, assuming that's Python, Node, or Java. But, this is the other place I feel will need to be improved.
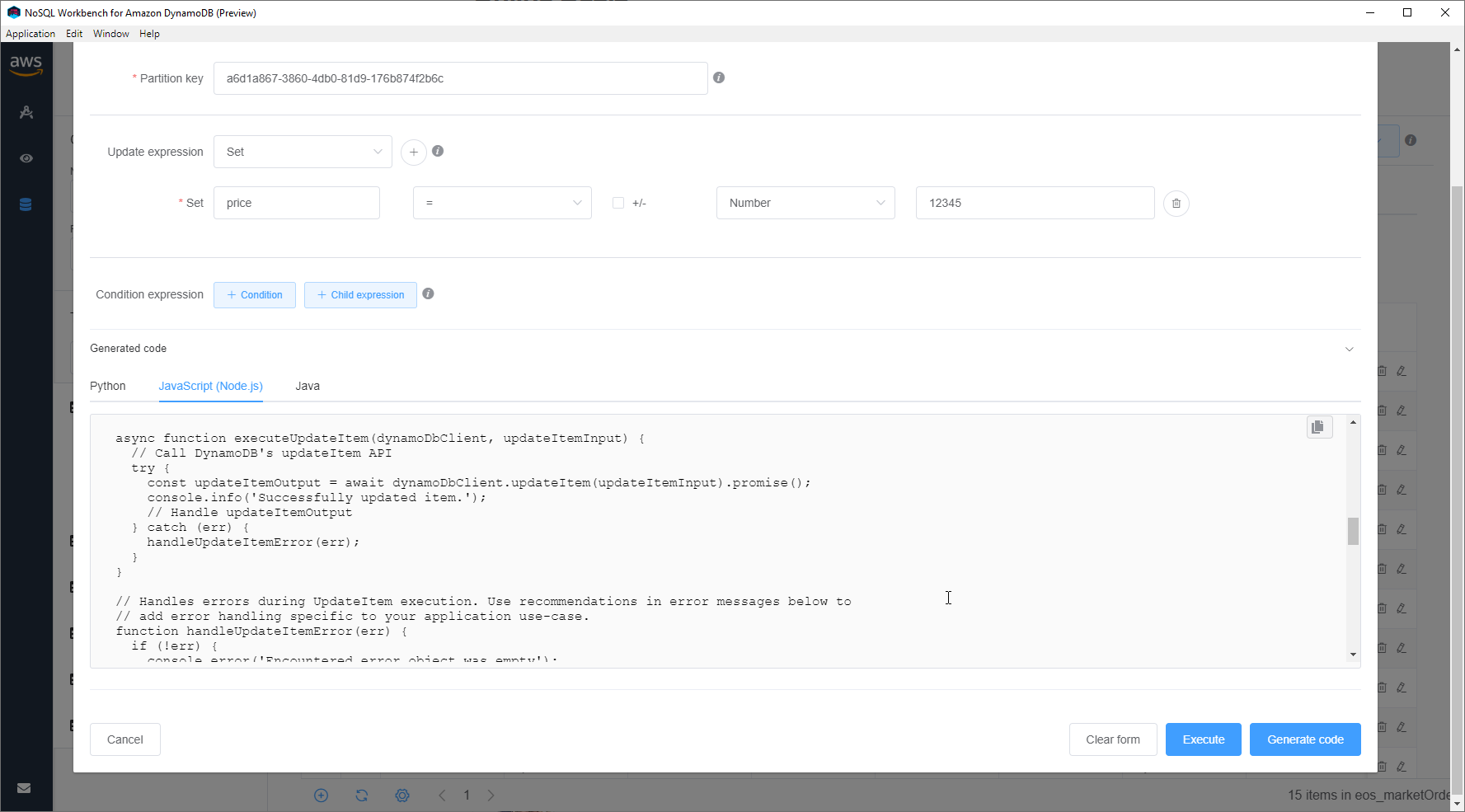 No TypeScript, no DocumentClient, no thank you!
No TypeScript, no DocumentClient, no thank you!
Generation is a tricky problem to solve. In the case of the Node code I realized there wasn't going to be much value in using it. While it's generally written well, there are too many variables to mean that this will be useful to many. It doesn't fit into my pattern of using DynamoDB (through the DocumentClient).
This could maybe be solved by letting me bring my own templates to use.
Where does this fit in my tool-chain?
Well, from a development standpoint, it could be more useful than the AWS Console. But without the easy inline editing of data, I'd likely fall back to using the Console enough that this tool would never be started in the first place and remain an un-highlighted icon at the bottom of my screen. Yet, I could see the modeller being really nice, as I've fat-fingered a number of table defintions in YAML files in the past. Once a CDK Construct is created that will turn the JSON output into a useful CloudFormation template I think it'll be a production-worthy tool.
The Operation Builder isn't an obivous win for me, yet. I'll have to use it more before I could say how useful it really is.
As for visualization, I'll probably be using it quite a bit during demonstrations or training sessions. The design team did a nice job here.
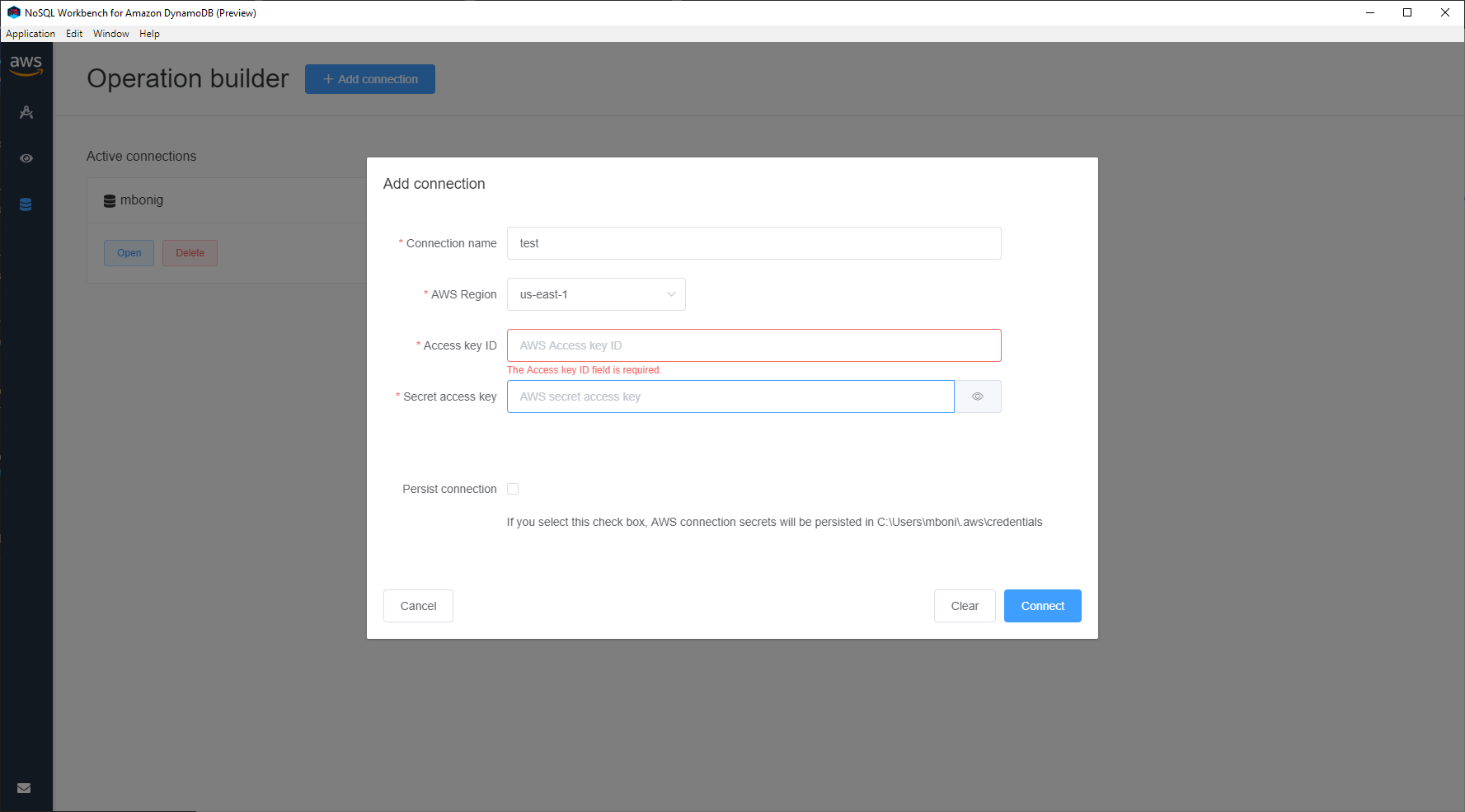 I gotta give you what now?
I gotta give you what now?
Wait, you want what now?
The way the DynamoDB Client manages AWS credentials feels very unfinished to me. I've had my config and credentials stored in `~/.aws` files for quite some time and the fact that it doesn't read those, and possibly overrites them, is something that needs to be resolved quickly.
And now I'm left confused about the audience for this product. Is it for beginners? Seems to be with the sample data, data modeling tools, and the table management built right in. But, it doesn't quite hold the user's hand enough, in my opinion and I fear it is teaching people that letting this tool manage your table definitions is a good idea.
Is it for advanced users? Not quite sure. The JSON output is a good feature that allows advanced users to take advantage of the data models, but this shouldn't be a requirement to do things properly. And having the tool push model changes directly to AWS feels like a deal-killer and bad practice.